NVMe RAG System - Intelligent Document Q&A
Overview
Developed a professional Retrieval-Augmented Generation (RAG) system specifically designed for the NVMe Base Specification documentation. The system enables intelligent question-answering and context retrieval for technical NVMe specifications, combining vector-based semantic search with large language model generation for accurate, context-aware responses with source citations.
Problem Statement
Technical documentation like NVMe specifications is dense, complex, and difficult to navigate. Engineers and developers need quick, accurate answers to specific questions but face challenges in finding relevant information across hundreds of pages. Traditional keyword search fails to understand semantic meaning and context, while reading entire specifications is time-consuming and inefficient.
Approach
Implemented a multi-stage RAG pipeline with semantic document chunking for context preservation. Used ChromaDB for vector storage with sentence-transformers (multi-qa-MiniLM-L6) for dense embeddings. Integrated Ollama with Gemma 3 (12B quantized) for local LLM inference. Built sophisticated query translation and analysis to improve retrieval accuracy. Implemented reranking pipeline for context relevance scoring and session management for conversation history. The system supports multiple retrieval strategies (basic, hybrid, reranked) and answer styles (concise, detailed, technical).
Visualizations
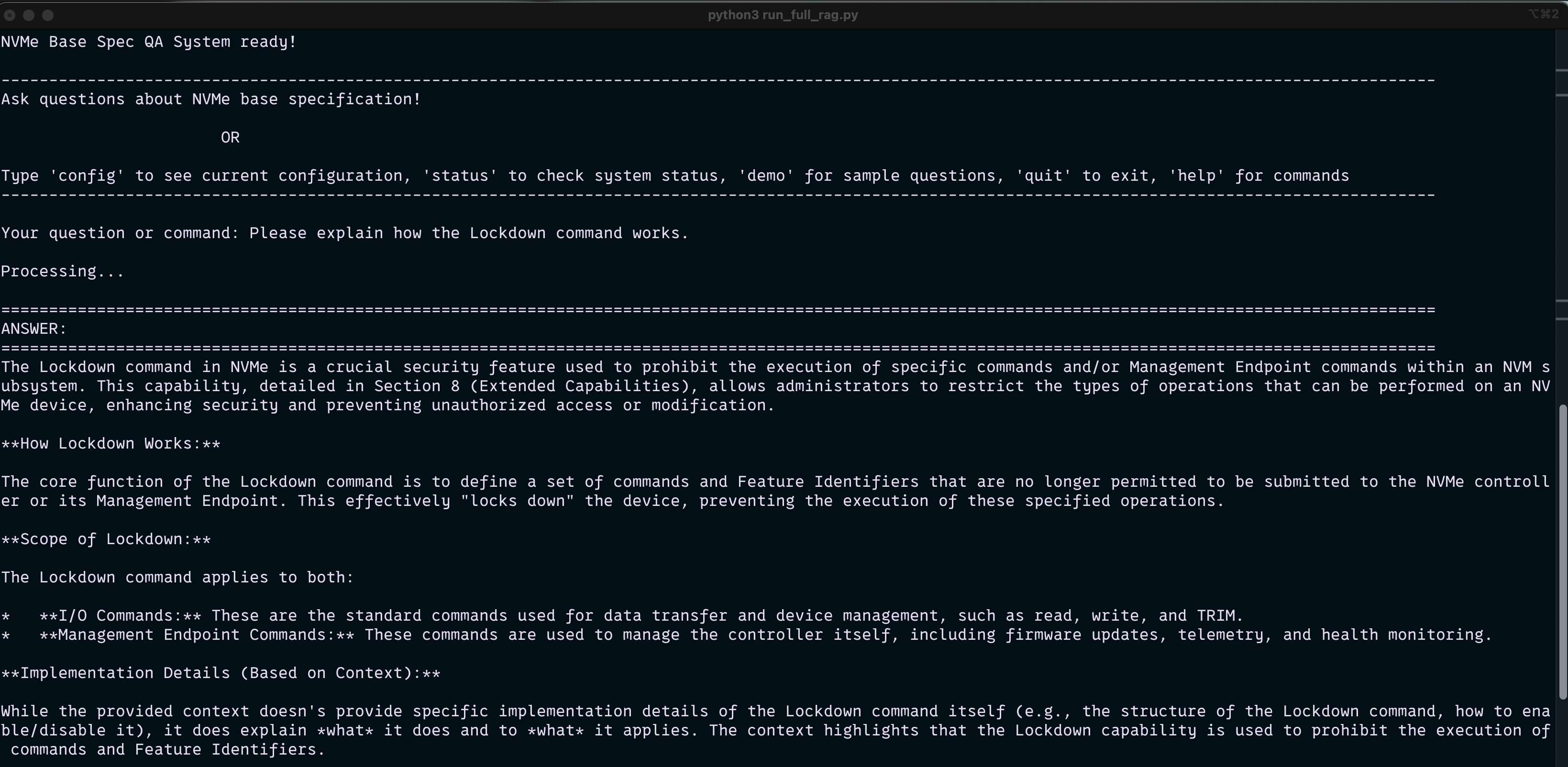
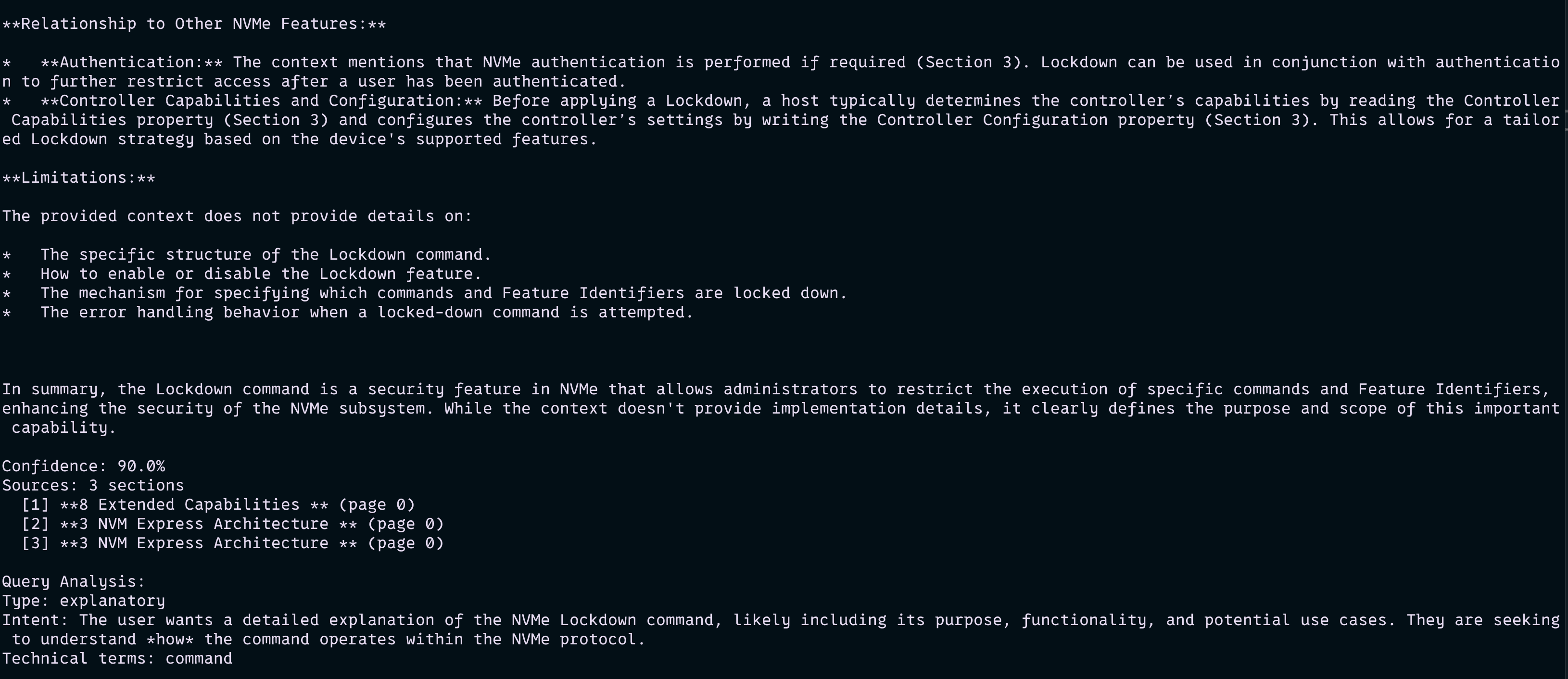
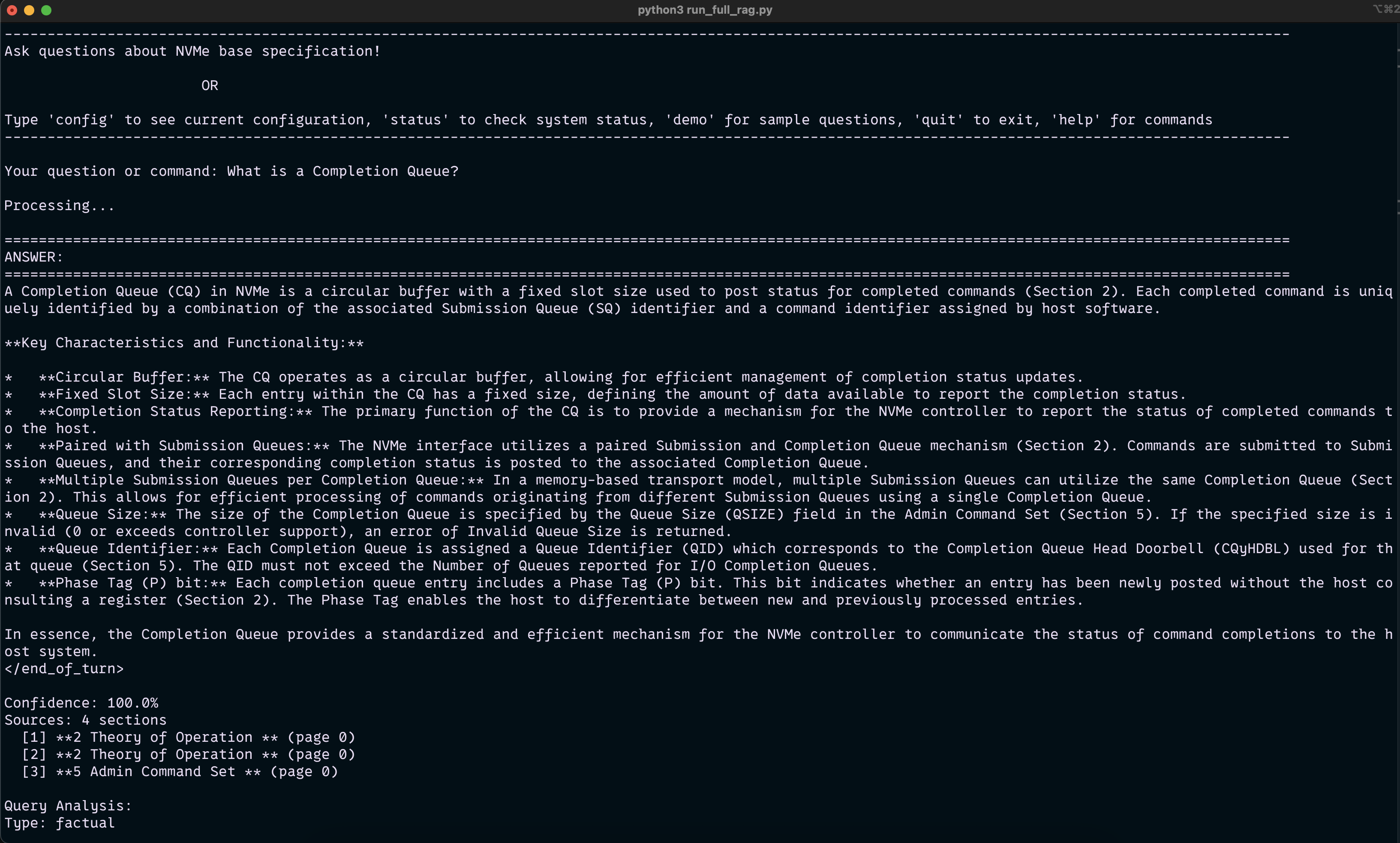
Results
Successfully processes NVMe specification documents with semantic chunking and generates context-aware answers with source citations. The reranked retrieval strategy achieved improved relevance scores compared to basic similarity search. Query translation enhanced retrieval accuracy for complex technical questions. The system provides follow-up question suggestions and maintains conversation context across sessions. Supports real-time question-answering with sub-second response times for most queries.